Copilot Studio で PDF や画像ファイルを扱うケースは、領収書 OCR、契約書解析、申請書デジタル化など、多くの業務フローで共通する基本スキルです。
特に、トピックで受け取ったファイルを Power Automate に渡して処理したい場合、ファイルの扱い方と正しいマッピング方法を理解しておくことが重要です。
目次
流れ
Copilot Studio のトピックでは、質問ノードまたは Teams 添付を通じて PDF や画像を受け取ることができる。
受け取ったファイルは Name / ContentType / Content(Base64) を持つレコードとして扱われる。
Copilot Studio のトピック変数は Content というキーを持っているが、Power Automate が受け取りたいのは contentBytes。
そのため、Power Fx で { contentBytes, name } のレコードを再構築する必要がある。
Power Automate 側では、渡された contentBytes を AI Builder に接続し、PDF や画像の文字を読み取る。
テキスト化後は抽出、整形、保存など自由に処理できる。
Copilot Studio でファイルを受け取る
Copilot Studio では、次の 2 つの方法でユーザーがアップロードしたファイルを取得できます。
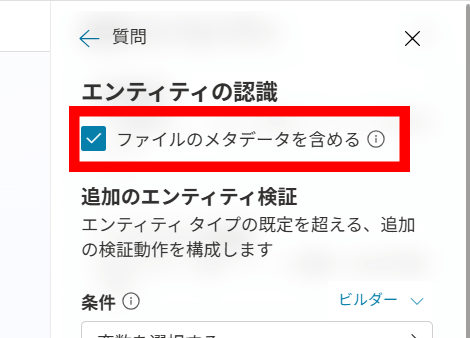
① 質問ノードで受け取る方法
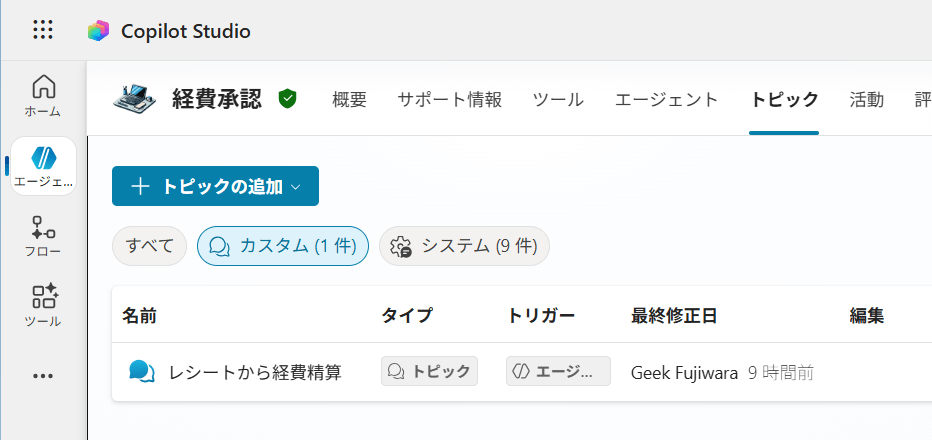
- 質問ノードの Identify を「File」に設定します。
- 「Include file metadata」をオンにします。
- これにより、変数に次のようなレコードが格納されます。
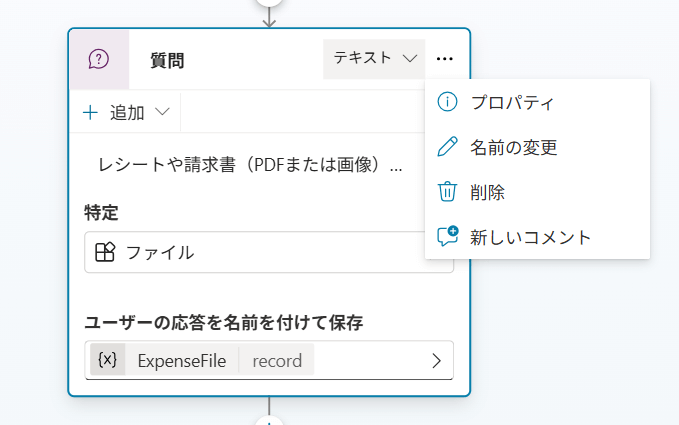
{
Name: "receipt.pdf",
ContentType: "application/pdf",
Content: "Base64データ"
}
② Teams などの添付ファイルを自動取得する方法
ユーザーが添付の形式でメッセージにファイルを添付している場合は、次の Power Fx で先頭の添付を取得できます。
First(System.Activity.Attachments)どちらの方法でも、Content は Base64 のまま保持されます。このままでは Power Automate が期待する形式ではないため、次の Step で変換します。
Power Automate に渡すための Record を組み立てます
Copilot Studio のファイル変数は Content というキーで Base64 を持っています。
一方で、Power Automate 側は contentBytes というキー名を前提にファイルを受け取ります。
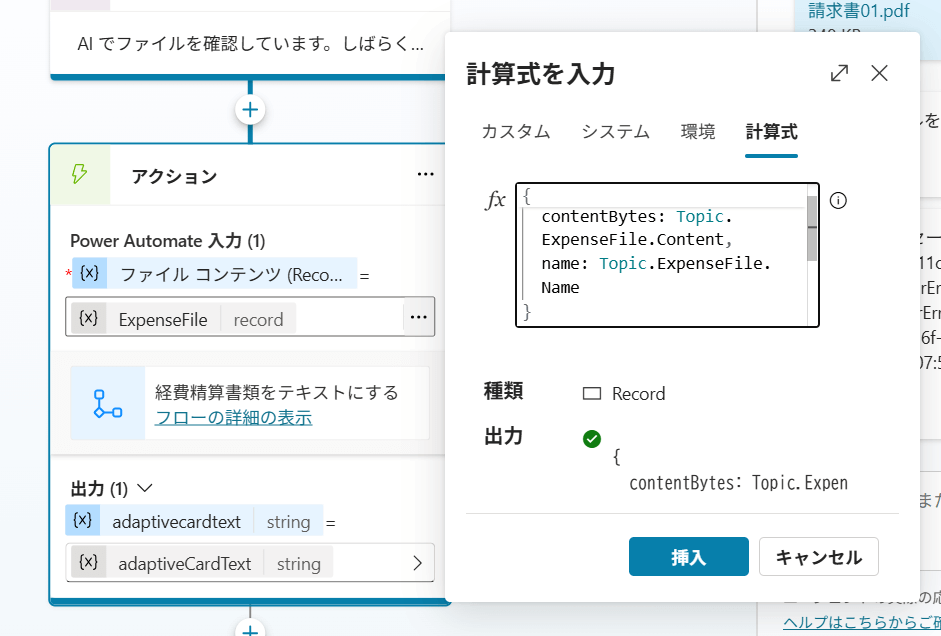
そのため、トピックのアクションノード側で Power Fx によってレコードを組み直します。
{
contentBytes: Topic.変数名.Content,
name: Topic.変数名.Name
}Power Automate のフローには、Copilot Studio からの Record 型入力 を用意しておきます。
この入力に contentBytes と name が届きますので、AI Builder の OCR へつなぎます。
テキスト化後は、日付・金額の抽出や、Dataverse / SharePoint 保存、Teams 通知、承認ワークフローなどに展開できます。
使用するアクション: Recognize text in an image or a PDF document
ファイル入力欄に contentBytes を指定します。
OCR の結果は「全文」「ページ単位」「行単位」で取得できます。
この仕組みを押さえるとできること
一度「Content → contentBytes の正しいマッピング」を理解してしまえば、さまざまな自動化に応用できます。
- 経費精算: 領収書の読取 → 金額・日付の抽出 → 自動申請
- 契約書レビュー: PDF 受け取り → テキスト抽出 → 要点サマリー
- 人事: 応募書類受け取り → OCR → データベース登録
- 文書管理: ファイル受け取り → SharePoint 登録 → Chat で要約提示
基礎はシンプルですが、効果は大きいです。まずはこの 3 ステップ(受け取り → 変換 → OCR)を確実に押さえることをおすすめします。