テキスト分割スキルにより、検索結果を分割したテキストとしても返答します。
目次
関連記事
セマンティック検索
テキスト分割スキルによるインデックスの分割は、単にインデックスをある文字長をベースに分割してインデックスとともに配列形式で保存する機能です。
そもそもテキスト分割スキルは検索に機能を持たせるサービスではなく、あくまで「インデックスを分割して保存もしてくれる」サービスです。
したがって検索してみると、ヒットした箇所だけでなく、すべてのテキスト分割した配列を返します。
ヒットした箇所のみ返してほしいときにはセマンティック検索が有効です。
 Cognitive Search でSemantic Search を有効にする
Cognitive Search でSemantic Search を有効にする
テキスト分割スキルの有効化
今回利用するAzure OpenAI Searvice のスキルの有効化手順はこちらで紹介しています。
 Azure Cognitive Search のテキスト分割スキルを有効化する
Azure Cognitive Search のテキスト分割スキルを有効化する
サンプルシナリオ
今回、ドキュメントとして参考にするのは「化学品のGHS分類とSDS解説.pdf」を利用してみます。

このドキュメントをインプットとし、エアゾールに関するリスクを回答を生成するシナリオを実現します。
PDFの文字すべてを読み込ませるケースとフィルターしたテキストだけのケースの文字数を比較してみます。
まずはPower Automate を用いてフローを作成します。
Power Automate フローの作成
ソリューションを作成してフローを作成します。
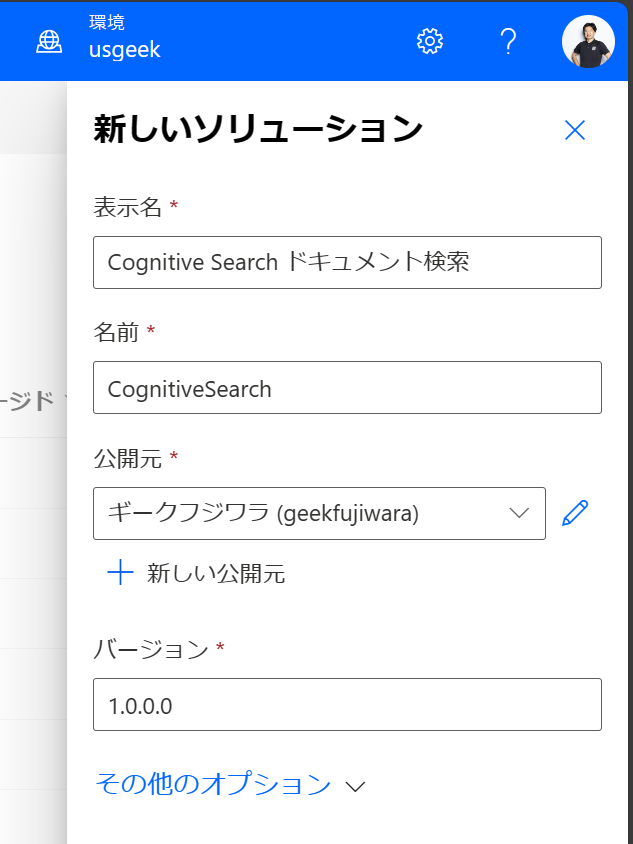
新しいクラウドフローを作成します。今回はPower Appsから起動したとして、Power Apps V2コネクタからの起動とします。
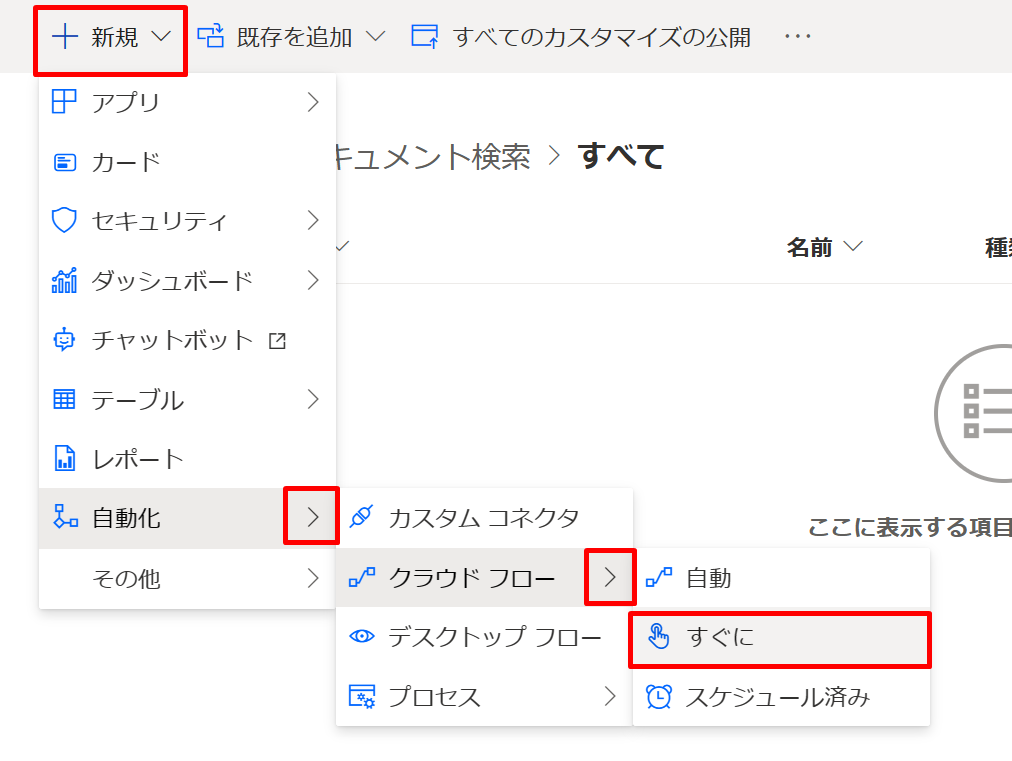
このようにトリガーを選択してフローを作成します。
Azure Cognitive Search のエンドポイントとキーの取得
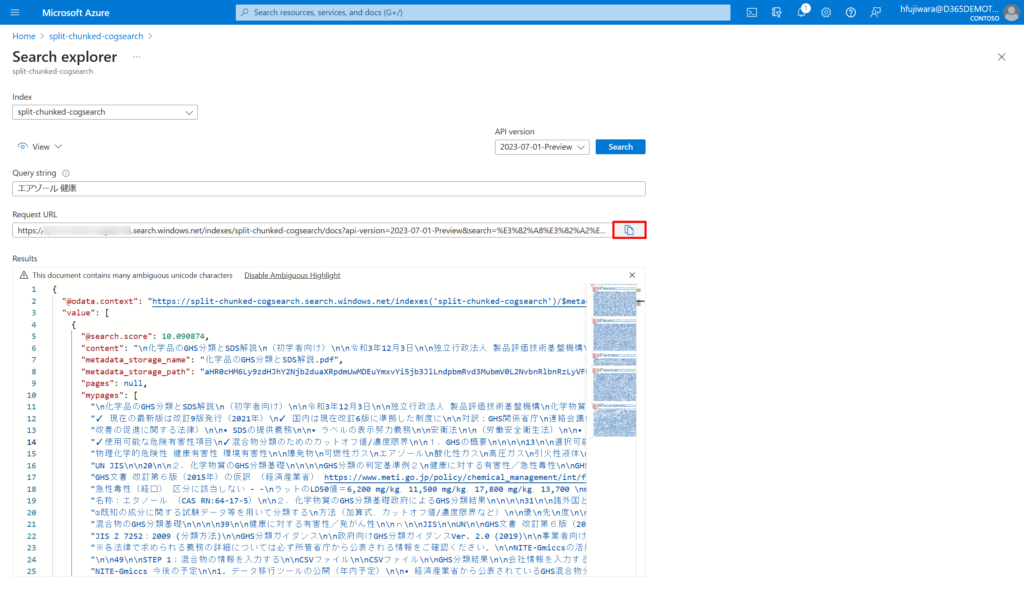
作成済みのCognitive Search をAzure Portal から確認します。
Search Explorer からエンドポイントを確認します。
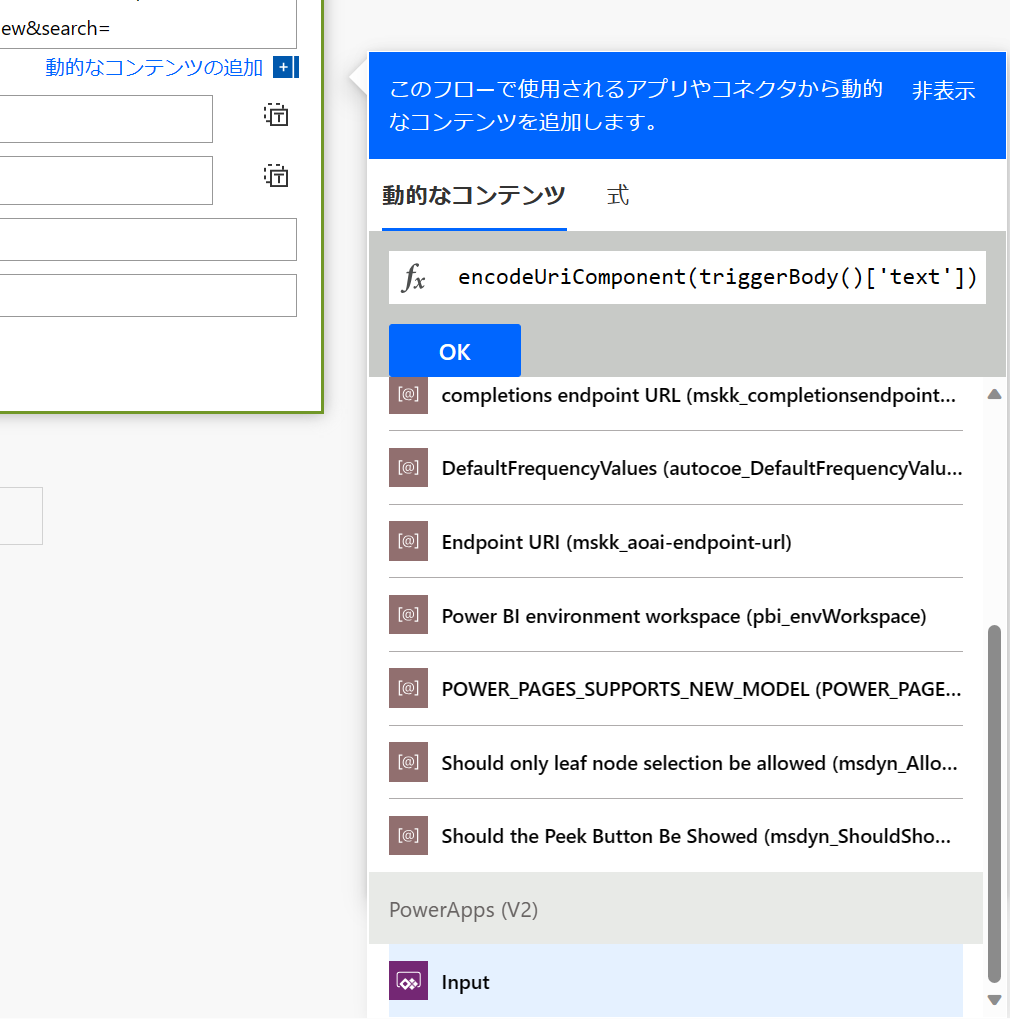
Power Automate に戻ります。encodeUrlComponent 関数を利用してPower Apps から受け取った検索語をエンコードします。
api-key を設定します。
Power Portal の設定にKeyは存在します。
テスト実行
Search Explorer と同じように実行してみます。

テストの結果、Search Explorer と同じくテキスト分割された結果が返ってきています。

文字数の比較
この中からそのままContent (ドキュメント全文取得)した場合との文字数を比較してみます。
フィルターは以下のように設定します。
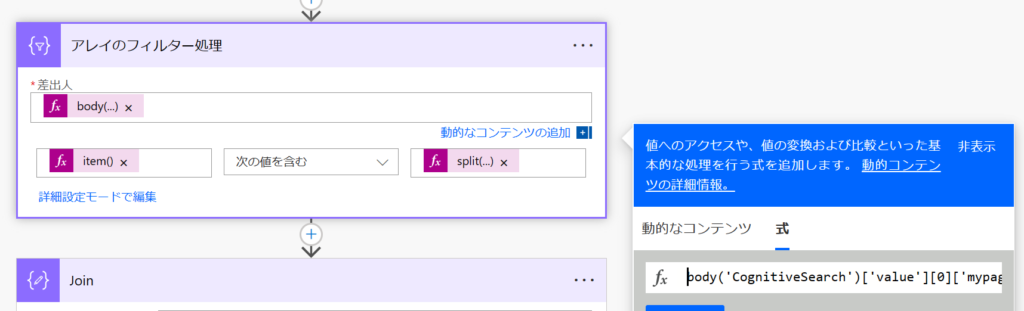
以下のように入力することで配列形式で取得することができます。これを「差出人」のフィールドに設定します。
body('HTTPリクエストのアクション名')['value'][0]['mypages']「次の値を含む」の評価の左側と右側には以下を設定してください。
左側
フィルター対象の配列から一行ずつを取り出して評価するときの項目を設定するには以下のように書きます。
item()右側
split関数を利用して半角スペース区切りの検索キーワードの情報を半角スペースで区切って配列にします。その配列から最初のキーワードを出力します。
split('半角スペース区切りの検索キーワード', ' ')[0]
アレイのフィルター処理のアクションの後、出力されるデータは配列形式のため、テキスト形式にします。ここではjoin関数を利用して半角スペース区切りで結合します。
結果をテキストにします。
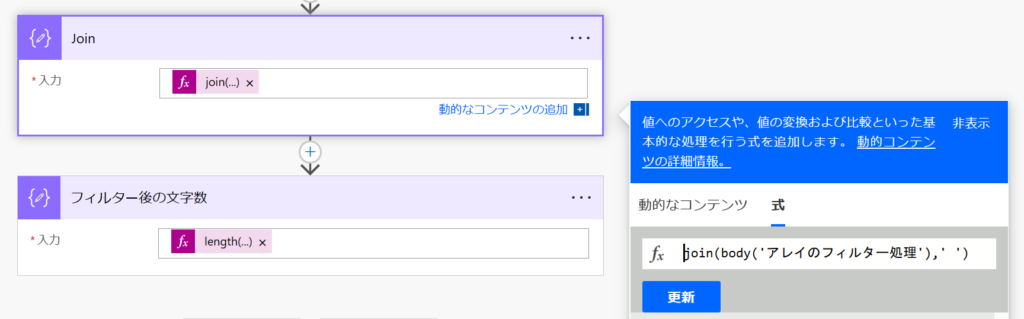
join(body('アレイのフィルター処理'), ' ')テストのため、文字数を計算します。文字数のカウントはlength関数で実行できます。
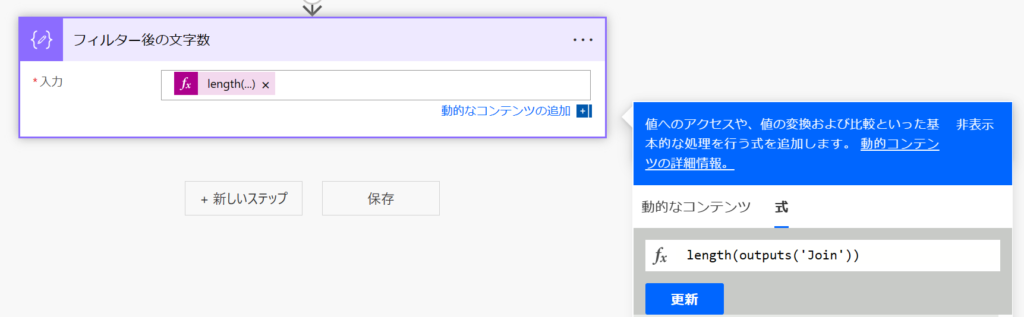
length(outputs('Join'))結果
全文での文字数は約30,000文字でした。
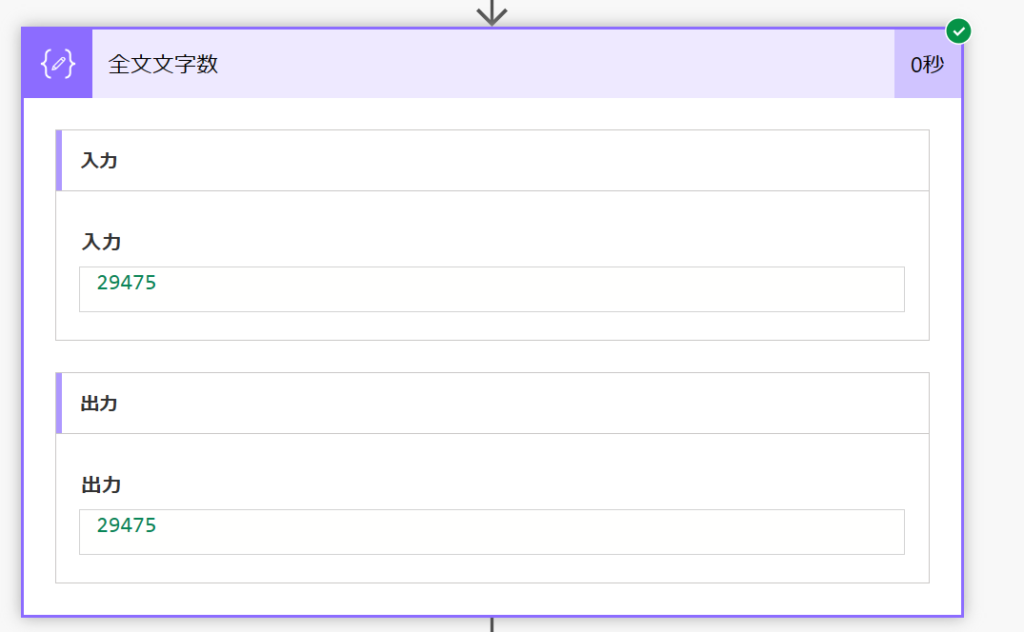
フィルター後の文字数は約5,000文字でした。
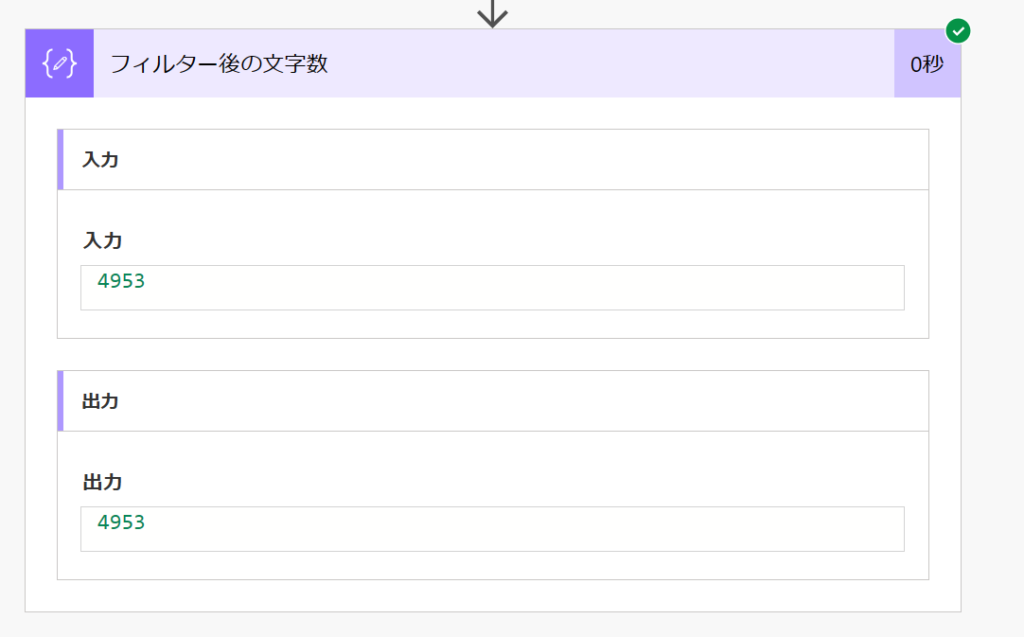
この文書のケースでは、該当箇所のフィルターによる抽出により、インプットとなる文字数を大幅に節約する事ができました。
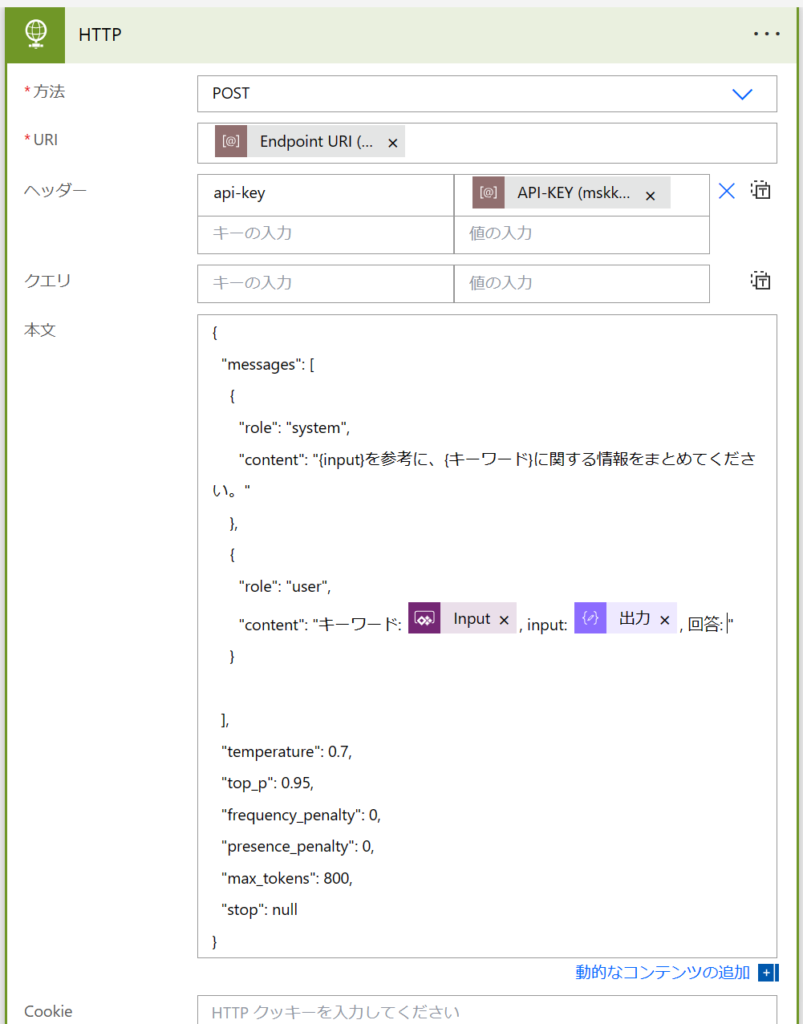
Azure OpenAI Searvice (GPT3.5t 16K) での要約結果
以下のようなコンテントが返答されました。インプットしたプロンプトは以下のとおりです。
結果は以下のように返ってきました。
かなり専門的な内容について、文書を参考に回答してくれています。
エアゾールは、GHS(国連グローバルハーモナイズドシステム)の「危険有害性」の一つとして分類されています。エアゾールは、液体や固体の微粒子が気体の媒体中に分散した形態を指し、スプレー缶やエアロゾル缶などで使用されています。
エアゾールの「物理化学的危険性」としては、可燃性ガスや高圧ガスの性質を持ち、引火性や爆発性のリスクがあります。また、「健康に対する有害性」としては、急性毒性や皮膚腐食性、眼に対する重篤な損傷性などのリスクがあります。
GHSにおけるエアゾールの分類は、混合物の分類方法によって行われます。エアゾールの分類には、混合物としてのデータがあればそれを使用する方法や、つなぎの原則(希釈、製造バッチ、濃縮など)を用いる方法があります。また、既知の成分に関する試験データを用いて分類する方法もあります。
具体的なエアゾールのGHS分類結果は、国連GHS文書や各国の法規制によって異なる場合があります。各国や地域では、エアゾールに対して使用可能なGHS分類結果が公開されている場合もありますが、これらはあくまで参考であり、使用を強制するものではありません。
以上が、エアゾールに関する情報の概要です。詳細な情報は、国連GHS文書や各国の法規制を参考にすることをおすすめします。まとめ
全文に対して要約させることはトークン数的に難しい、またコストがかかるので、この方式は有効です。
Azure Cognitive Search のテキスト分割スキルを有効にする方法は以下でご紹介しています。
Azure Cognitive Search のテキスト分割スキルを有効化する